8 Discrete Optimization
Most algorithms in this book assume that the design variables are continuous. However, sometimes design variables must be discrete. Common examples of discrete optimization include scheduling, network problems, and resource allocation. This chapter introduces some techniques for solving discrete optimization problems.
8.1 Binary, Integer, and Discrete Variables¶
Discrete optimization variables can be of three types: binary (sometimes called zero-one), integer, and discrete. A light switch, for example, can only be on or off and is a binary decision variable that is either 0 or 1. The number of wheels on a vehicle is an integer design variable because it is not useful to build a vehicle with half a wheel. The material in a structure that is restricted to titanium, steel, or aluminum is an example of a discrete variable. These cases can all be represented as integers (including the discrete categories, which can be mapped to integers). An optimization problem with integer design variables is referred to as integer programming, discrete optimization, or combinatorial optimization.[1]Problems with both continuous and discrete variables are referred to as mixed-integer programming.
Unfortunately, discrete optimization is nondeterministic polynomial-time complete, or NP-complete, which means that we can easily verify a solution, but there is no known approach to find a solution efficiently. Furthermore, the time required to solve the problem becomes much worse as the problem size grows.
It is possible to construct algorithms that find the global optimum of discrete problems, such as exhaustive searches. Exhaustive search ideas can also be used for continuous problems (see Section 7.5, for example, but the cost is much higher). Although an exhaustive search may eventually arrive at the correct answer, executing that algorithm to completion is often not practical, as Example 8.1 highlights. Discrete optimization algorithms aim to search the large combinatorial space more efficiently, often using heuristics and approximate solutions.
8.2 Avoiding Discrete Variables¶
Even though a discrete optimization problem limits the options and thus conceptually sounds easier to solve, discrete optimization problems are usually much more challenging to solve than continuous problems. Thus, it is often desirable to find ways to avoid using discrete design variables. There are a few approaches to accomplish this.
The first approach is an exhaustive search. We just discussed how exhaustive search scales poorly, but sometimes we have many continuous variables and only a few discrete variables with few options. In that case, enumerating all options is possible. For each combination of discrete variables, the optimization is repeated using all continuous variables. We then choose the best feasible solution among all the optimizations. This approach yields the global optimum, assuming that the continuous optimization finds the global optimum in the continuous variable space.
A second approach is rounding. We can optimize the discrete design variables for some problems as if they were continuous and round the optimal design variable values to integer values afterward. This can be a reasonable approach if the magnitude of the design variables is large or if there are many continuous variables and few discrete variables. After rounding, it is best to repeat the optimization once more, allowing only the continuous design variables to vary. This process might not lead to the true optimum, and the solution might not even be feasible. Furthermore, if the discrete variables are binary, rounding is generally too crude.
However, rounding is an effective and practical approach for many problems.
Dynamic rounding is a variation of the rounding approach. Rather than rounding all continuous variables at once, dynamic rounding is an iterative process. It rounds only one or a subset of the discrete variables, fixes them, and re-optimizes the remaining variables using continuous optimization. The process is repeated until all discrete variables are fixed, followed by one last optimization with the continuous variables.
A third approach to avoiding discrete variables is to change the parameterization. For example, one approach in wind farm layout optimization is to parametrize the wind turbine locations as a discrete set of points on a grid. To turn this into a continuous problem, we could parametrize the position of each turbine using continuous coordinates. The trade-off of this continuous parameterization is that we can no longer change the number of turbines, which is still discrete. To re-parameterize, sometimes a continuous alternative is readily apparent, but more often, it requires a good deal of creativity.
Sometimes, an exhaustive search is not feasible, rounding is unacceptable, and a continuous representation is impossible. Fortunately, there are several techniques for solving discrete optimization problems.
8.3 Branch and Bound¶
A popular method for solving integer optimization problems is the branch-and-bound method. Although it is not always the most efficient method,[2]it is popular because it is robust and applies to a wide variety of discrete problems. One case where the branch-and-bound method is especially effective is solving convex integer programming problems where it is guaranteed to find the global optimum. The most common convex integer problem is a linear integer problem (where all the objectives and constraints are linear in the design variables). This method can be extended to nonconvex integer optimization problems, but it is generally far less effective for those problems and is not guaranteed to find the global optimum. In this section, we assume linear mixed-integer problems but include a short discussion on nonconvex problems.
A linear mixed-integer optimization problem can be expressed as follows:
where represents the set of all positive integers, including zero.
8.3.1 Binary Variables¶
Before tackling the integer variable case, we explore the binary variable case, where the discrete entries in must be 0 or 1. Most integer problems can be converted to binary problems by adding additional variables and constraints. Although the new problem is larger, it is usually far easier to solve.
The key to a successful branch-and-bound problem is a good relaxation. Relaxation aims to construct an approximation of the original optimization problem that is easier to solve. Such approximations are often accomplished by removing constraints.
Many types of relaxation are possible for a given problem, but for linear mixed-integer programming problems, the most natural relaxation is to change the integer constraints to continuous bound constraints .
In other words, we solve the corresponding continuous linear programming problem, also known as an LP (discussed in Section 11.2). If the solution to the original LP happens to return all binary values, that is the final solution, and we terminate the search. If the LP returns fractional values, then we need to branch.
Branching is done by adding constraints and solving the new optimization problems. For example, we could branch by adding constraints on to the relaxed LP, creating two new optimization problems: one with the constraint and another with the constraint . This procedure is then repeated with additional branching as needed.
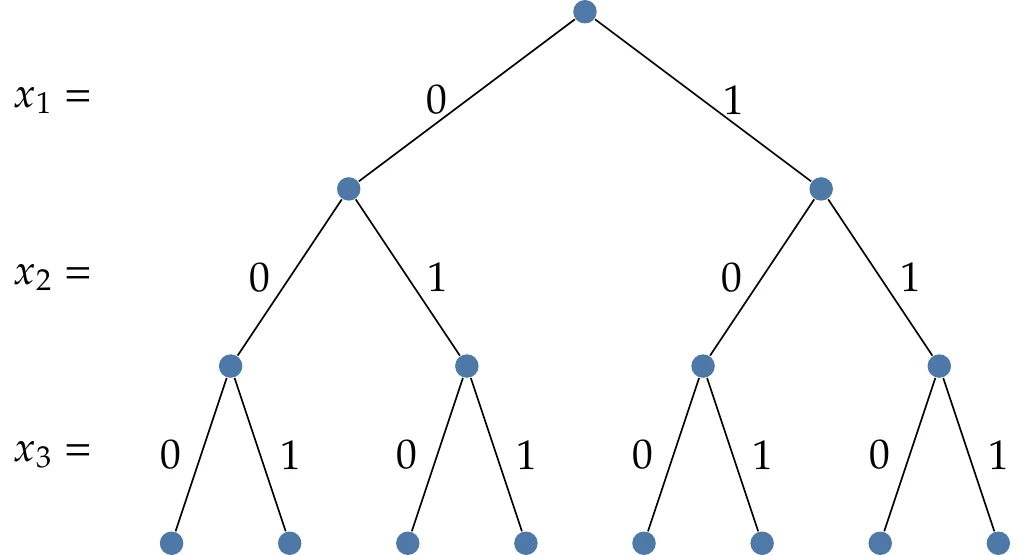
Figure 8.2:Enumerating the options for a binary problem with branching.
Figure 8.2 illustrates the branching concept for binary variables. If we explored all of those branches, this would amount to an exhaustive search. The main benefit of the branch-and-bound algorithm is that we can find ways to eliminate branches (referred to as pruning) to narrow down the search scope.
There are two ways to prune. If any of the relaxed problems is infeasible, we know that everything from that node downward (i.e., that branch) is also infeasible. Adding more constraints cannot make an infeasible problem feasible again. Thus, that branch is pruned, and we go back up the tree. We can also eliminate branches by determining that a better solution cannot exist on that branch. The algorithm keeps track of the best solution to the problem found so far.
If one of the relaxed problems returns an objective that is worse than the best we have found, we can prune that branch. We know this because adding constraints always leads to a solution that is either the same or worse, never better (assuming that we find the global optimum, which is guaranteed for LP problems).
The solution from a relaxed problem provides a lower bound—the best that could be achieved if continuing on that branch. The logic for these various possibilities is summarized in Algorithm 8.1.
The initial best known solution can be set as if nothing is known, but if a known feasible solution exists (or can be found quickly by some heuristic), providing any finite best point can speed up the optimization.
Many variations exist for the branch-and-bound algorithm. One variation arises from the choice of which variables to branch on at a given node.
One common strategy is to branch on the variable with the largest fractional component. For example, if , we could branch on or because both are fractional. We hypothesize that we are more likely to force the algorithm to make faster progress by branching on variables that are closer to midway between integers. In this case, that value would be . We would choose to branch on the value closest to 0.5, that is,
Another variation of branch and bound arises from how the tree search is performed. Two common strategies are depth-first and breadth-first. A depth-first strategy continues as far down as possible (e.g., by always branching left) until it cannot go further, and then it follows right branches. A breadth-first strategy explores all nodes on a given level before increasing depth. Various other strategies exist. In general, we do not know beforehand which one is best for a given problem.
Depth-first is a common strategy because, in the absence of more information about a problem, it is most likely to be the fastest way to find a solution—reaching the bottom of the tree generally forces a solution. Finding a solution quickly is desirable because its solution can then be used as a lower bound on other branches.
The depth-first strategy requires less memory storage because breadth-first must maintain a longer history as the number of levels increases. In contrast, depth-first only requires node storage equal to the number of levels.
8.3.2 Integer Variables¶
If the problem cannot be cast in binary form, we can use the same procedure with integer variables. Instead of branching with two constraints ( and ), we branch with two inequality constraints that encourage integer solutions. For example, if the variable we branched on was , we would branch with two new problems with the following constraints: or .
Nonconvex mixed-integer problems can also be used with the branch-and-bound method and generally use this latter strategy of forming two branches of continuous constraints. In this case, the relaxed problem is not a convex problem, so there is no guarantee that we have found a lower bound for that branch. Furthermore, the cost of each suboptimization problem is increased. Thus, for nonconvex discrete problems, this approach is usually only practical for a relatively small number of discrete design variables.
8.4 Greedy Algorithms¶
Greedy algorithms are among the simplest methods for discrete optimization problems. This method is more of a concept than a specific algorithm. The implementation varies with the application. The idea is to reduce the problem to a subset of smaller problems (often down to a single choice) and then make a locally optimal decision. That decision is locked in, and then the next small decision is made in the same manner. A greedy algorithm does not revisit past decisions and thus ignores much of the coupling between design variables.
The greedy algorithm used in Example 8.6 is easy to apply and scalable but does not generally find the global optimum. To find that global optimum, we have to consider the impact of our choices on future decisions. A method to achieve this for certain problem structures is discussed in the next section.
Even for a fixed problem, there are many ways to construct a greedy algorithm. The advantage of the greedy approach is that the algorithms are easy to construct, and they bound the computational expense of the problem. One disadvantage of the greedy approach is that it usually does not find an optimal solution (and in some cases finds the worst solution!1). Furthermore, the solution is not necessarily feasible. Despite the disadvantages, greedy algorithms can sometimes quickly find solutions reasonably close to an optimal solution.
8.5 Dynamic Programming¶
Dynamic programming is a valuable approach for discrete optimization problems with a particular structure. This structure can also be exploited in continuous optimization problems and problems beyond optimization. The required structure is that the problem can be posed as a Markov chain (for continuous problems, this is called a Markov process). A Markov chain or process satisfies the Markov property, where a future state can be predicted from the current state without needing to know the entire history. The concept can be generalized to a finite number of states (i.e., more than one but not the entire history) and is called a variable-order Markov chain.
If the Markov property holds, we can transform the problem into a recursive one. Using recursion, a smaller problem is solved first, and then larger problems are solved that use the solutions from the smaller problems.
This approach may sound like a greedy optimization, but it is not. We are not using a heuristic but fully solving the smaller problems. Because of the problem structure, we can reuse those solutions. We will illustrate this in examples. This approach has become particularly useful in optimal control and some areas of economics and computational biology. More general design problems, such as the propeller example (Example 8.2), do not fit this type of structure (i.e., choosing the number of blades cannot be broken up into a smaller problem separate from choosing the material).
A classic example of a Markov chain is the Fibonacci sequence, defined as follows:
We can compute the next number in the sequence using only the last two states.[4]We could implement the computation of this sequence using recursion, as shown algorithmically in Algorithm 8.2 and graphically in Figure 8.10 for .
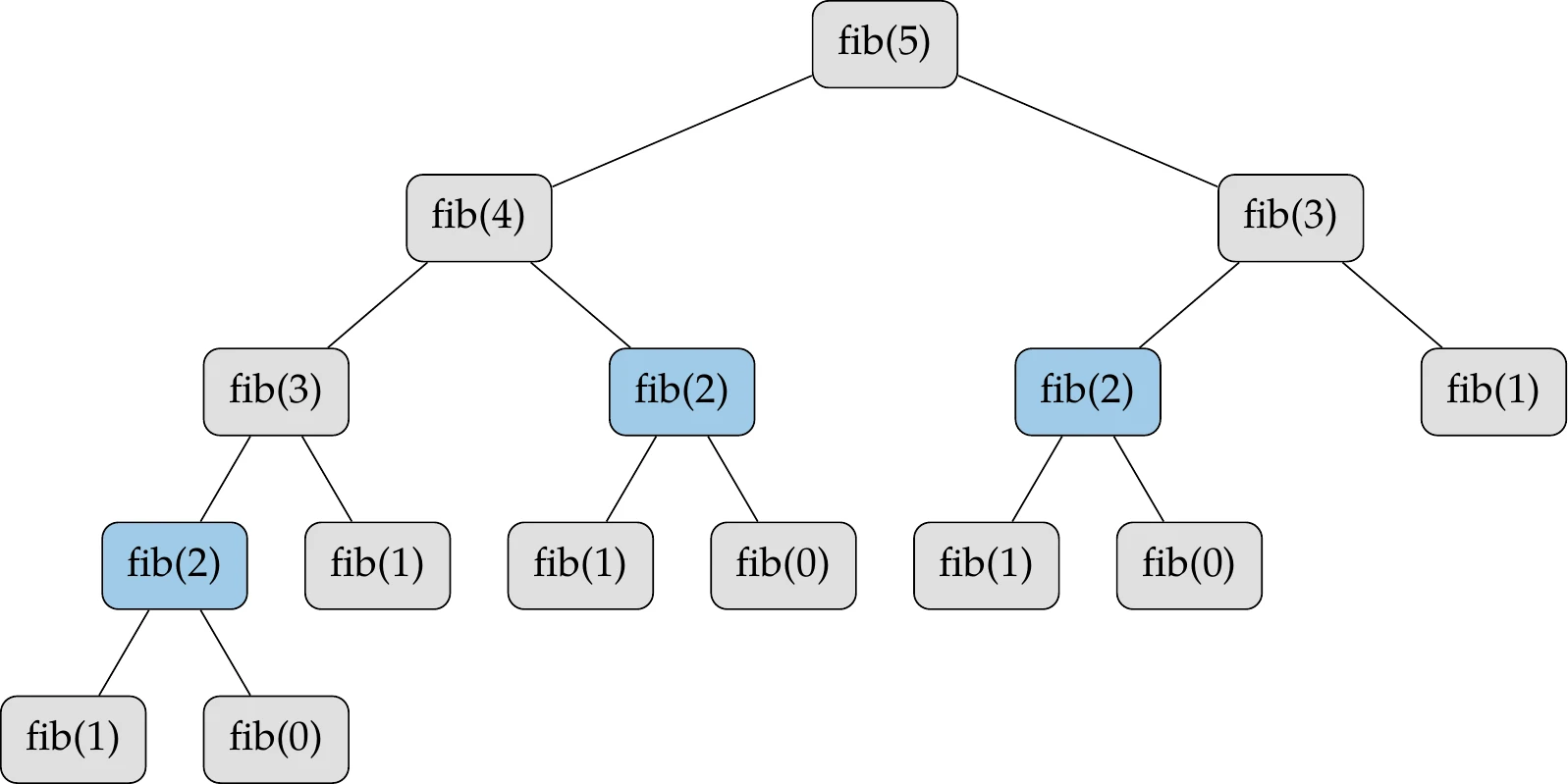
Figure 8.10:Computing Fibonacci sequence using recursion. The function fib(2) is highlighted as an example to show the repetition that occurs in this recursive procedure.
Although this recursive procedure is simple, it is inefficient. For example, the calculation for fib(2) (highlighted in Figure 8.10) is repeated multiple times. There are two main approaches to avoiding this inefficiency. The first is a top-down procedure called memoization, where we store previously computed values to avoid having to compute them again. For example, the first time we need fib(2), we call the fib function and store the result (the value 1). As we progress down the tree, if we need fib(2) again, we do not call the function but retrieve the stored value instead.
A bottom-up procedure called tabulation is more common. This procedure is how we would typically show the Fibonacci sequence. We start from the bottom () and work our way forward, computing each new value using the previous states. Rather than using recursion, this involves a simple loop, as shown in Algorithm 8.3. Whereas memoization fills entries on demand, tabulation systematically works its way up, filling in entries. In either case, we reduce the computational complexity of this algorithm from exponential complexity (approximately ) to linear complexity ().
These procedures can be applied to optimization, but before introducing examples, we formalize the mathematics of the approach. One main difference in optimization is that we do not have a set formula like a Fibonacci sequence. Instead, we need to make a design decision at each state, which changes the next state. For example, in the problem shown in Figure 8.9, we decide which path to take.
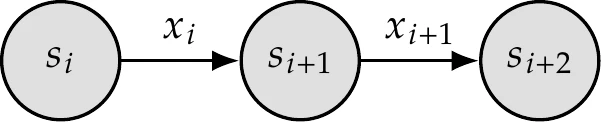
Figure 8.11:Diagram of state transitions in a Markov chain.
Mathematically, we express a given state as and make a design decision , which transitions us to the next state (Figure 8.11),
where is a transition function.[5]At each transition, we compute the cost function .[6]For generality, we specify a cost function that may change at each iteration :
We want to make a set of decisions that minimize the sum of the current and future costs up to a certain time, which is called the value function,
where defines the time horizon up to which we consider the cost. For continuous problems, the time horizon may be infinite. The value function (Equation 8.6) is the minimum cost, not just the cost for some arbitrary set of decisions.[7]Bellman’s principle of optimality states that because of the structure of the problem (where the next state only depends on the current state), we can determine the best solution at this iteration if we already know all the optimal future decisions . Thus, we can recursively solve this problem from the back (bottom) by determining , then , and so on back to . Mathematically, this recursive procedure is captured by the Bellman equation:
We can also express this equation in terms of our transition function to show the dependence on the current decision:
To illustrate the concepts more generally, consider another classic problem in discrete optimization—the knapsack problem. In this problem, we have a fixed set of items we can select from. Each item has a weight and a cost . Because the knapsack problem is usually written as a maximization problem and cost implies minimization, we should use value instead. However, we proceed with cost to be consistent with our earlier notation. The knapsack has a fixed capacity (a scalar) that cannot be exceeded.
The objective is to choose the items that yield the highest total cost subject to the capacity of our knapsack. The design variables are either 1 or 0, indicating whether we take or do not take item . This problem has many practical applications, such as shipping, data transfer, and investment portfolio selection.
The problem can be written as
In its present form, the knapsack problem has a linear objective and linear constraints, so branch and bound would be a good approach. However, this problem can also be formulated as a Markov chain, so we can use dynamic programming. The dynamic programming version accommodates variations such as stochasticity and other constraints more easily.
To pose this problem as a Markov chain, we define the state as the remaining capacity of the knapsack and the number of items we have already considered. In other words, we are interested in , where is the value function (optimal value given the inputs), is the remaining capacity in the knapsack, and indicates that we have already considered items 1 through (this does not mean we have added them all to our knapsack, only that we have considered them). We iterate through a series of decisions deciding whether to take item or not, which transitions us to a new state where increases and may decrease, depending on whether or not we took the item.
The real problem we are interested in is , which we solve using tabulation. Starting at the bottom, we know that for any . This means that no matter the capacity, the value is 0 if we have not considered any items yet. To work forward, consider a general case considering item , with the assumption that we have already solved up to item for any capacity. If item cannot fit in our knapsack (), then we cannot take the item. Alternatively, if the weight is less than the capacity, we need to decide whether to select item or not. If we do not, then the value is unchanged, and . If we do select item , then our value is plus the best we could do with the previous items but with a capacity that was smaller by : . Whichever of these decisions yields a better value is what we should choose.
To determine which items produce this cost, we need to add more logic. To keep track of the selected items, we define a selection matrix of the same size as (note that this matrix is indexed starting at zero in both dimensions). Every time we accept an item , we register that in the matrix as . Algorithm 8.4 summarizes this process.
We fill all entries in the matrix to extract the last value . For small numbers, filling this matrix (or table) is often illustrated manually, hence the name tabulation. As with the Fibonacci example, using dynamic programming instead of a fully recursive solution reduces the complexity from to , which means it is pseudolinear. It is only pseudolinear because there is a dependence on the knapsack size. For small capacities, the problem scales well even with many items, but as the capacity grows, the problem scales much less efficiently. Note that the knapsack problem requires integer weights. Real numbers can be scaled up to integers (e.g., 1.2, 2.4 become 12, 24). Arbitrary precision floats are not feasible given the number of combinations to search across.
Like greedy algorithms, dynamic programming is more of a technique than a specific algorithm. The implementation varies with the particular application.
8.6 Simulated Annealing¶
Simulated annealing[8]is a methodology designed for discrete optimization problems. However, it can also be effective for continuous multimodal problems, as we will discuss.
The algorithm is inspired by the annealing process of metals. The atoms in a metal form a crystal lattice structure. If the metal is heated, the atoms move around freely. As the metal cools down, the atoms slow down, and if the cooling is slow enough, they reconfigure into a minimum-energy state. Alternatively, if the metal is quenched or cooled rapidly, the metal recrystallizes with a different higher-energy state (called an amorphous metal).
From statistical mechanics, the Boltzmann distribution (also called Gibbs distribution) describes the probability of a system occupying a given energy state:
where is the energy level, is the temperature, and is Boltzmann’s constant. This equation shows that as the temperature decreases, the probability of occupying a higher-energy state decreases, but it is not zero. Therefore, unlike in classical mechanics, an atom could jump to a higher-energy state with some small probability. This property imparts an exploratory nature to the optimization algorithm, which avoids premature convergence to a local minimum. The temperature level provides some control on the level of expected exploration.
An early approach to simulate this type of probabilistic thermodynamic model was the Metropolis algorithm.4 In the Metropolis algorithm, the probability of transitioning from energy state to energy state is formulated as
where this probability is limited to be no greater than 1. This limit is needed because the exponent yields a value greater than 1 when , which would be nonsensical. Simulated annealing leverages this concept in creating an optimization algorithm.
In the optimization analogy, the objective function is the energy level. Temperature is a parameter controlled by the optimizer, which begins high and is slowly “cooled” to drive convergence. At a given iteration, the design variables are given by , and the objective (or energy) is given by . A new state is selected at random in the neighborhood of . If the energy level decreases, the new state is accepted. If the energy level increases, the new state might still be accepted with probability
where Boltzmann’s constant is removed because it is just an arbitrary scale factor in the optimization context. Otherwise, the state remains unchanged. Constraints can be handled in this algorithm without resorting to penalties by rejecting any infeasible step.
We must supply the optimizer with a function that provides a random neighboring design from the set of possible design configurations. A neighboring design is usually related to the current design instead of picking a pure random design from the entire set. In defining the neighborhood structure, we might wish to define transition probabilities so that all neighbors are not equally likely. This type of structure is common in Markov chain problems. Because the nature of different discrete problems varies widely, we cannot provide a generic neighbor-selecting algorithm, but an example is shown later for the specific case of a traveling salesperson problem.
Finally, we need to determine the annealing schedule (or cooling schedule), a process for decreasing the temperature throughout the optimization. A common approach is an exponential decrease:
where is the initial temperature, is the cooling rate, and is the iteration number. The cooling rate is a number close to 1, such as 0.8–0.99. Another simple approach to iterate toward zero temperature is as follows:
where the exponent is usually in the range of 1–4. A higher exponent corresponds to spending more time at low temperatures. In many approaches, the temperature is kept constant for a fixed number of iterations (or a fixed number of successful moves) before moving to the next decrease. Many methods are simple schedules with a predetermined rate, although more complex adaptive methods also exist.[9] The annealing schedule can substantially impact the algorithm’s performance, and some experimentation is required to select an appropriate schedule for the problem at hand. One essential requirement is that the temperature should start high enough to allow for exploration. This should be significantly higher than the maximum expected energy change (change in objective) but not so high that computational time is wasted with too much random searching. Also, cooling should occur slowly to improve the ability to recover from a local optimum, imitating the annealing process instead of the quenching process.
The algorithm is summarized in Algorithm 8.5; for simplicity in the description, the annealing schedule uses an exponential decrease at every iteration.
The simulated annealing algorithm can be applied to continuous multimodal problems as well. The motivation is similar because the initial high temperature permits the optimizer to escape local minima, whereas a purely descent-based approach would not. By slowly cooling, the initial exploration gives way to exploitation. The only real change in the procedure is in the neighbor function. A typical approach is to generate a random direction and choose a step size proportional to the temperature. Thus, smaller, more conservative steps are taken as the algorithm progresses. If bound constraints are present, they would be enforced at this step. Purely random step directions are not particularly efficient for many continuous problems, particularly when most directions are ill-conditioned (e.g., a narrow valley or near convergence). One variation adopts concepts from the Nelder–Mead algorithm (Section 7.3) to improve efficiency.7 Overall, simulated annealing has made more impact on discrete problems compared with continuous ones.
8.7 Binary Genetic Algorithms¶
The binary form of a genetic algorithm (GA) can be directly used with discrete variables. Because the binary form already requires a discrete representation for the population members, using discrete design variables is a natural fit. The details of this method were discussed in Section 7.6.1.
8.8 Summary¶
This chapter discussed various strategies for approaching discrete optimization problems. Some problems can be well approximated using rounding, can be reparameterized in a continuous way, or only have a few discrete combinations, allowing for explicit enumeration. For problems that can be posed as linear (or convex in general), branch and bound is effective. If the problem can be posed as a Markov chain, dynamic programming is a useful method.
If none of these categorizations are applicable, then a stochastic method, such as simulated annealing or GAs, may work well. These stochastic methods typically struggle as the dimensionality of the problem increases. However, simulated annealing can scale better for some problems if there are clever ways to quickly evaluate designs in the neighborhood, as is done with the traveling salesperson problem. An alternative to these various algorithms is to use a greedy strategy, which can scale well. Because this strategy is a heuristic, it usually results in a loss in solution quality.
Problems¶
Sometimes subtle differences in meaning are intended, but typically, and in this chapter, these terms can be used interchangeably.
Better methods may exist that leverage the specific problem structure, some of which are discussed in this chapter.
This is a form of the knapsack problem, which is a classic problem in discrete optimization discussed in more detail in the following section.
We can also convert this to a standard first-order Markov chain by defining and considering our state to be . Then, each state only depends on the previous state.
For some problems, the transition function is stochastic.
It is common to use discount factors on future costs.
We use and for the scalars in Equation 8.6 instead of Greek letters because the connection to “value” and “cost” is clearer.
- Gutin, G., Yeo, A., & Zverovich, A. (2002). Traveling salesman should not be greedy: domination analysis of greedy-type heuristics for the TSP. Discrete Applied Mathematics, 117(1–3), 81–86. 10.1016/s0166-218x(01)00195-0
- Kirkpatrick, S., Gelatt, C. D., & Vecchi, M. P. (1983). Optimization by simulated annealing. Science, 220(4598), 671–680. 10.1126/science.220.4598.671
- Černý, V. (1985). Thermodynamical approach to the traveling salesman problem: An efficient simulation algorithm. Journal of Optimization Theory and Applications, 45(1), 41–51. 10.1007/bf00940812
- Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., Teller, A. H., & Teller, E. (1953). Equation of state calculations by fast computing machines. Journal of Chemical Physics. 10.2172/4390578
- Andresen, B., & Gordon, J. M. (1994). Constant thermodynamic speed for minimizing entropy production in thermodynamic processes and simulated annealing. Physical Review E, 50(6), 4346–4351. 10.1103/physreve.50.4346
- Lin, S. (1965). Computer solutions of the traveling salesman problem. Bell System Technical Journal, 44(10), 2245–2269. 10.1002/j.1538-7305.1965.tb04146.x
- Press, W. H., Wevers, J. C. A., Flannery, B. P. ., Teukolsky, S. A., Vetterling, W. T., Flannery, B. P., & Vetterling, W. T. . (1992). Numerical Recipes in C: The Art of Scientific Computing. Cambridge University Press.