General nonlinear optimization problems are difficult to solve. Depending on the particular optimization algorithm, they may require tuning parameters, providing derivatives, adjusting scaling, and trying multiple starting points. Convex optimization problems do not have any of those issues and are thus easier to solve. The challenge is that these problems must meet strict requirements. Even for candidate problems with the potential to be convex, significant experience is usually needed to recognize and utilize techniques that reformulate the problems into an appropriate form.
Convex optimization problems have desirable characteristics that make them more predictable and easier to solve. Because a convex problem has provably only one optimum, convex optimization methods always converge to the global minimum. Solving convex problems is straightforward and does not require a starting point, parameter tuning, or derivatives, and such problems scale well up to millions of design variables.1
All we need to solve a convex problem is to set it up appropriately; there is no need to worry about convergence, local optima, or noisy functions. Some convex problems are so straightforward that they are not recognized as an optimization problem and are just thought of as a function or operation. A familiar example of the latter is the linear-least-squares problem (described previously in Section 10.3.1 and revisited in a subsequent section).
Although these are desirable properties, the catch is that convex problems must satisfy strict requirements. Namely, the objective and all inequality constraints must be convex functions, and the equality constraints must be affine.[1]A function f is convex if
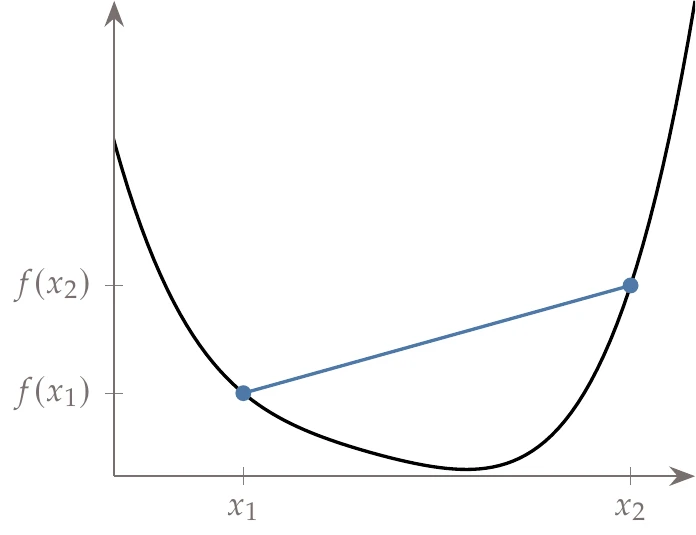
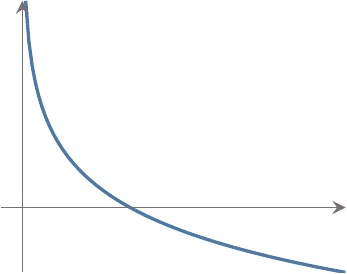
for all x1 and x2 in the domain, where 0≤η≤1. This requirement is illustrated in Figure 11.1 for the one-dimensional case. The right-hand side of the inequality is just the equation of a line from f(x1) to f(x2) (the blue line), whereas the left-hand side is the function f(x) evaluated at all points between x1 and x2 (the black curve).
Figure 11.1:Convex function definition in the one-dimensional case: The function (black line) must be below a line that connects any two points in the domain (blue line).
The inequality says that the function must always be below a line joining any two points in the domain. Stated informally, a convex function looks something like a bowl.
Unfortunately, even these strict requirements are not enough. In general, we cannot identify a given problem as convex or take advantage of its structure to solve it efficiently and must therefore treat it as a general nonlinear problem. There are two approaches to taking advantage of convexity. The first one is to directly formulate the problem in a known convex form, such as a linear program or a quadratic program (discussed later in this chapter). The second option is to use disciplined convex optimization, a specific set of rules and mathematical functions that we can use to build up a convex problem. By following these rules, we can automatically translate the problem into an efficiently solvable form.
Although both of these approaches are straightforward to apply, they also expose the main weakness of these methods: we need to express the objective and inequality constraints using only these elementary functions and operations. In most cases, this requirement means that the model must be simplified.
Often, a problem is not directly expressed in a convex form, and a combination of experience and creativity is needed to reformulate the problem in an equivalent manner that is convex.
Simplifying models usually results in a fidelity reduction. This is less problematic for optimization problems intended to be solved repeatedly, such as in optimal control and machine learning, which are domains in which convex optimization is heavily used. In these cases, simplification by local linearization, for example, is less problematic because the linearization can be updated in the next time step. However, this fidelity reduction is problematic for design applications.
In design scenarios, the optimization is performed once, and the design cannot continue to be updated after it is created. For this reason, convex optimization is less frequently used for design applications, except for some limited uses in geometric programming, a topic discussed in more detail in Section 11.6.
This chapter just introduces convex optimization and is not a replacement for more comprehensive textbooks on the topic.[2] We focus on understanding what convex optimization is useful for and describing the most widely used forms.
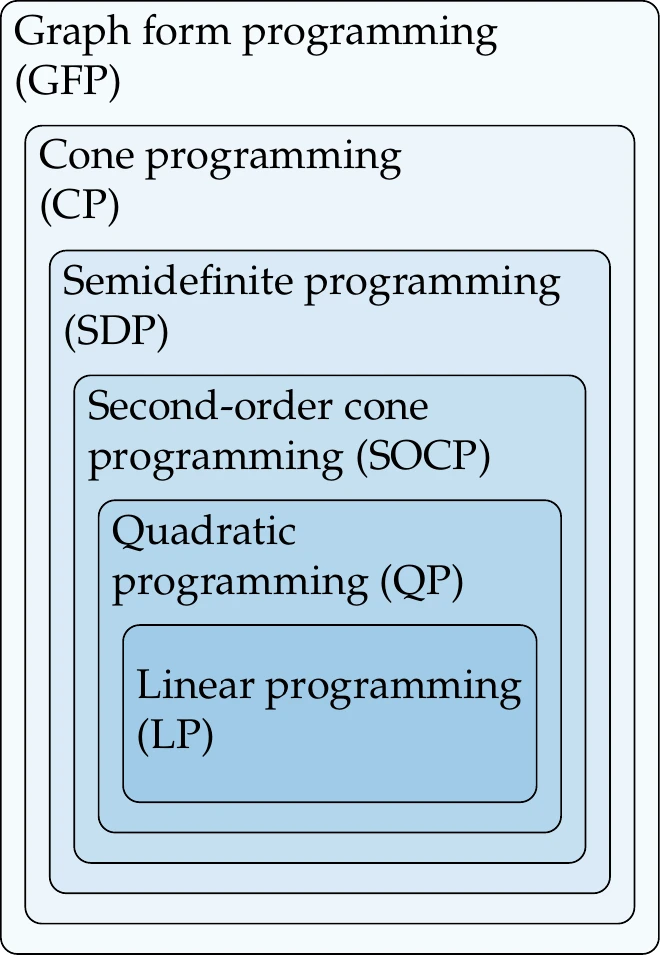
The known categories of convex optimization problems include linear programming, quadratic programming, second-order cone programming, semidefinite programming, cone programming, and graph form programming. Each of these categories is a subset of the next (Figure 11.2).[3]
We focus on the first three because they are the most widely used, including in other chapters in this book. The latter three forms are less frequently formulated directly. Instead, users apply elementary functions and operations and the rules specified by disciplined convex programming, and a software tool transforms the problem into a suitable conic form that can be solved. Section 11.5 describes this procedure.
Figure 11.2:Relationship between various convex optimization problems.
After covering the three main categories of convex optimization problems, we discuss geometric programming. Geometric programming problems are not convex, but with a change of variables, they can be transformed into an equivalent convex form, thus extending the types of problems that can be solved with convex optimization.
where f, b, and d are vectors and A and C are matrices. All LPs are convex.
LPs frequently occur with allocation or assignment problems, such as choosing an optimal portfolio of stocks, deciding what mix of products to build, deciding what tasks should be assigned to each worker, or determining which goods to ship to which locations. These types of problems frequently occur in domains such as operations research, finance, supply chain management, and transportation.[4]A common consideration with LPs is whether or not the variables should be discrete. In Example 11.1, xi is a continuous variable, and purchasing fractional amounts of food may or may not be possible, depending on the type of food. Suppose we were performing an optimal stock allocation. In that case, we can purchase fractional amounts of stock. However, if we were optimizing how much of each product to manufacture, it might not be feasible to build 32.4 products. In these cases, we need to restrict the variables to be integers using integer constraints. These types of problems require discrete optimization algorithms, which are covered in Chapter 8. Specifically, we discussed a mixed-integer LP in (Section 8.3).
A quadratic program (QP) has a quadratic objective and linear constraints. Quadratic programming was introduced in Section 5.5 in the context of sequential quadratic programming. A general QP can be expressed as follows:
A QP is only convex if the matrix Q is positive semidefinite. If Q=0, a QP reduces to an LP.
One of the most common QP examples is least squares regression, which was discussed previously in Section 10.3.1 and is used in many applications such as data fitting.
The linear least-squares problem has an analytic solution if A has full rank, so the machinery of a QP is not necessary. However, we can add constraints in QP form to solve constrained least squares problems, which do not have analytic solutions in general.
One useful subset of SOCP is a quadratically constrained quadratic program (QCQP). A QCQP is the same as a QP but has quadratic inequality constraints instead of linear ones, that is,
xminimizesubject to21x⊺Qx+f⊺xAx+b=021x⊺Rix+ci⊺x+di≤0 for i=1,…,m,
where Q and R must be positive semidefinite for the QCQP to be convex. A QCQP reduces to a QP if R=0. We formulated QCQPs when solving trust-region problems in Section 4.5. However, for trust-region problems, only an approximate solution method is typically used.
Every QCQP can be expressed as an SOCP (although not vice versa). The QCQP in Equation 11.5 can be written in the equivalent form,
If we square both sides of the first and last constraints, this formulation is exactly equivalent to the QCQP where Q=2F⊺F, f=2F⊺g, Ri=2Gi⊺Gi, ci=2Gi⊺hi, and di=hi⊺hi. The matrices F and Gi are the square roots of the matrices Q and Ri, respectively (divided by 2), and would be computed from a factorization.
Disciplined convex optimization builds convex problems using a specific set of rules and mathematical functions. By following this set of rules, the problem can be translated automatically into a conic form that we can efficiently solve using convex optimization algorithms.5Table 1 shows several examples of convex functions that can be used to build convex problems. Notice that not all functions are continuously differentiable because this is not a requirement of convexity.
A disciplined convex problem can be formulated using any of these functions for the objective and inequality constraints. We can also use various operations that preserve convexity to build up more complex functions. Some of the more common operations are as follows:
Multiplying a convex function by a positive constant
Adding convex functions
Composing a convex function with an affine function (i.e., if f(x) is convex, then f(Ax+b) is also convex)
Taking the maximum of two convex functions
Although these functions and operations greatly expand the types of convex problems that we can solve beyond LPs and QPs, they are still restrictive within the broader scope of nonlinear optimization. Still, for objectives and constraints that require only simple mathematical expressions, there is the possibility that the problem can be posed as a disciplined convex optimization problem.
The original expression of a problem is often not convex but can be made convex through a transformation to a mathematically equivalent problem. These transformation techniques include implementing a change of variables, adding slack variables, or expressing the objective in a different form. Successfully recognizing and applying these techniques is a skill requiring experience.
A geometric program (GP) is not convex but can be transformed into an equivalent convex problem. GPs are formulated using monomials and posynomials. A monomial is a function of the following form:
where fi are posynomials, and hi are monomials. This problem does not fit into any of the convex optimization problems defined in the previous section, and it is not convex. This formulation is useful because we can convert it into an equivalent convex optimization problem.
First, we take the logarithm of the objective and of both sides of the constraints:
Let us examine the equality constraints further. Recall that hi is a monomial, so writing one of the constraints explicitly results in the following form:
The objective and inequality constraints are more complex because they are posynomials. The expression lnfi written in terms of a posynomial results in the following:
Because this is a sum of products, we cannot use the logarithm to expand each term. However, we still introduce the same change of variables (expressed as xi=eyi):
This is a log-sum-exp of an affine function. As mentioned in the previous section, log-sum-exp is convex, and a convex function composed of an affine function is a convex function. Thus, the objective and inequality constraints are convex in y. Because the equality constraints are also affine, we have a convex optimization problem obtained through a change of variables.
Unfortunately, many other functions do not fit this form (e.g., design variables that can be positive or negative, terms with negative coefficients, trigonometric functions, logarithms, and exponents). GP modelers use various techniques to extend usability, including using a Taylor series across a restricted domain, fitting functions to posynomials,7 and rearranging expressions to other equivalent forms, including implicit relationships.
Creativity and some sacrifice in fidelity are usually needed to create a corresponding GP from a general nonlinear programming problem. However, if the sacrifice in fidelity is not too great, there is a significant advantage because the formulation comes with all the benefits of convexity—guaranteed convergence, global optimality, efficiency, no parameter tuning, and limited scaling issues.
One extension to geometric programming is signomial programming. A signomial program has the same form, except that the coefficients ci can be positive or negative (the design variables xi must still be strictly positive). Unfortunately, this problem cannot be transformed into a convex one, so a global optimum is no longer guaranteed. Still, a signomial program can usually be solved using a sequence of geometric programs, so it is much more efficient than solving the general nonlinear problem. Signomial programs have been used to extend the range of design problems that can be solved using geometric programming techniques.89
Convex optimization problems are highly desirable because they do not require parameter tuning, starting points, or derivatives and converge reliably and rapidly to the global optimum.
The trade-off is that the form of the objective and constraints must meet stringent requirements. These requirements often necessitate simplifying the physics models and implementing clever reformulations. The reduction in model fidelity is acceptable in domains where optimizations are performed repeatedly in time (e.g., controls, machine learning) or for high-level conceptual design studies. Linear programming and quadratic programming, in particular, are widely used across many domains and form the basis of many of the gradient-based algorithms used to solve general nonconvex problems.
An affine function consists of a linear transformation and a translation. Informally, this type of function is often referred to as linear (including in this book), but strictly, these are distinct concepts. For example: Ax is a linear function in x, whereas Ax+b is an affine function in x.
In the machine learning community, this optimization problem is known as a support vector machine. This problem is an example of supervised learning because classification labels were provided. Classification can be done without labels but requires a different approach under the umbrella of unsupervised learning.
Diamond, S., & Boyd, S. (2015). Convex optimization with abstract linear operators. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Institute of Electrical. 10.1109/iccv.2015.84
Boyd, S. P., & Vandenberghe, L. (2004). Convex Optimization. Cambridge University Press.
Lobo, M. S., Vandenberghe, L., Boyd, S., & Lebret, H. (1998). Applications of second-order cone programming. Linear Algebra and Its Applications, 284(1–3), 193–228. 10.1016/s0024-3795(98)10032-0
Parikh, N., & Boyd, S. (2013). Block splitting for distributed optimization. Mathematical Programming Computation, 6(1), 77–102. 10.1007/s12532-013-0061-8
Grant, M., Boyd, S., & Ye, Y. (2006). Disciplined convex programming. In L. Liberti & N. Maculan (Eds.), Global Optimization—From Theory to Implementation (pp. 155–210). Springer. 10.1007/0-387-30528-9_7
Boyd, S., Kim, S.-J., Vandenberghe, L., & Hassibi, A. (2007). A tutorial on geometric programming. Optimization and Engineering, 8(1), 67–127. 10.1007/s11081-007-9001-7
Hoburg, W., Kirschen, P., & Abbeel, P. (2016). Data fitting with geometric-programming-compatible softmax functions. Optimization and Engineering, 17(4), 897–918. 10.1007/s11081-016-9332-3
Kirschen, P. G., York, M. A., Ozturk, B., & Hoburg, W. W. (2018). Application of signomial programming to aircraft design. Journal of Aircraft, 55(3), 965–987. 10.2514/1.c034378
York, M. A., Hoburg, W. W., & Drela, M. (2018). Turbofan engine sizing and tradeoff analysis via signomial programming. Journal of Aircraft, 55(3), 988–1003. 10.2514/1.c034463